:quality(85)//cloudfront-us-east-1.images.arcpublishing.com/infobae/SSR7LOYJ4ZD6LDFDG6DHQZRD5Q.JPG)
Die Technologie entwickelt sich ständig weiter und zeichnet verschiedene Bereiche, um neue Fähigkeiten und Funktionen zu erkunden. Eine davon ist Macht. Das Gesicht einer Person mit einer Stimme „rekonstruieren“.
Lernen Sprechen Sie 2 Gesicht Es wurde 2019 auf einer Konferenz zu Seh- und Erkennungsmethoden vorgestellt und zeigt, dass künstliche Intelligenz (KI) möglich ist. Verstehen Sie anhand kurzer Audioabschnitte, wie es einer Person geht.
Zu den Forschern des MIT Science and Research Project gehören Da-Hyun Ann, Tali Tekel, Sangil Kim, Inbar Mosseri, William D. Das Dokument erklärt, dass das Ziel von Freeman und Michael Rubinstein nicht darin besteht, die Gesichter von Menschen auf die gleiche Weise zu rekonstruieren, sondern sie zu erschaffen. Bild mit physikalischen Eigenschaften, die sich auf das analysierte Audio beziehen.
Früher haben sie dies erreicht Entwarf und trainierte das tiefe neuronale Netzwerk Es analysierte Millionen von Videos aus dem beliebten YouTube. Modellbau während der Ausbildung gelernt Stimmen Gesichtern zuordnenErmöglicht Ihnen zu produzieren Bilder mit physikalischen Merkmalen wie LautsprechernEinschließlich Alter, Geschlecht und Rasse.

Das Training wurde unter Anleitung und Anwendung durchgeführt Harmonie von Gesichtern und Stimmen Aus Internetvideos, ohne dass detaillierte physische Merkmale des Gesichts modelliert werden müssen.
„Unsere Rekonstruktionen, die direkt von Audio abgeleitet sind, zeigen die Interaktionen zwischen Gesichtern und Stimmen.
Sie erklärten, dass, da diese Studie aufgrund von Rasse und Privatsphäre wichtige Merkmale aufweisen könnte, der Unterhaltung der Gesichter keine spezifischen körperlichen Merkmale hinzugefügt wurden und dass sie genauso vielversprechend waren wie die anderen. System Maschinelles Lernen, Es verbessert sich im Laufe der Zeit, da seine Anwendung seine Wissensbibliothek erweitert.
Beweise aber gezeigt Speech 2 Face hat eine große Anzahl von Übereinstimmungen zwischen Gesichtern und StimmenEs gab auch einige Mängel, bei denen Rasse, Alter oder Geschlecht nicht mit dem verwendeten Sprachmodell übereinstimmten.
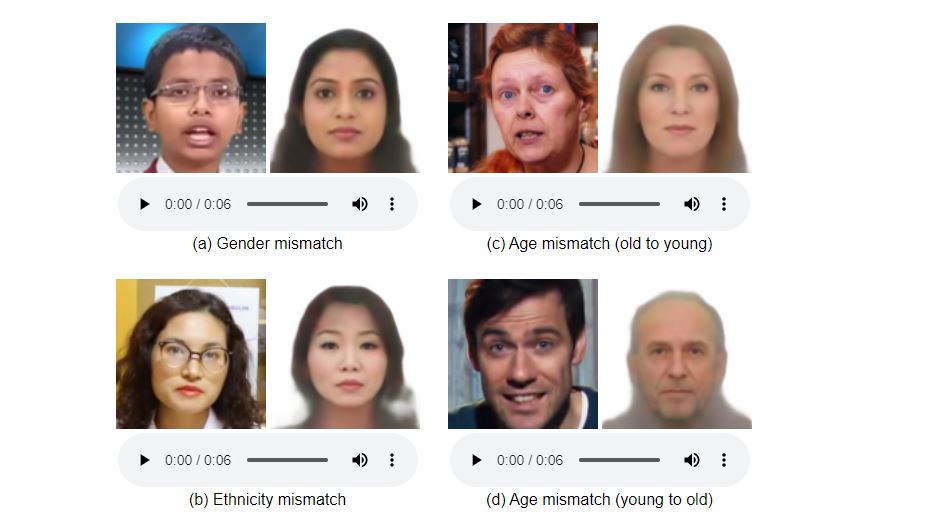
Ernennung zur Bereitstellung von Mustern Statistische Korrelationen zwischen Gesichtszügen und Stimme. Zu beachten ist, dass die KI aus YouTube-Videos gelernt hat, die nicht das wahre Modell der Weltbevölkerung darstellen, beispielsweise in einigen Sprachen Unstimmigkeiten mit Trainingsdaten zeigt.
In diesem Sinne kommt die Studie zu dem Schluss, dass diejenigen, die sich entscheiden, das System zu erforschen und zu modernisieren, das breitere Spektrum von Menschen und Stimmen berücksichtigen sollten. Mechanisches Lernen EIN Große Auswahl an Gesichtsanpassung und Unterhaltung.
Das Programm war in der Lage, die Stimme in den Cartoons nachzubilden, die unglaubliche Ähnlichkeiten mit den Stimmen in den analysierten Audios aufweisen.
Da diese Technologie auch für böswillige Zwecke verwendet werden kann, hält die Gesichtsunterhaltung das Ding nur nahe an der Person und zeigt nicht das ganze Gesicht, da dies die Privatsphäre der Menschen erschweren kann. Dennoch ist es erstaunlich, was Technologie aus Audiomodellen machen kann.
Weiterlesen:

„Forscher. Leser. Zukünftiges Teenager-Idol. Analytiker. Beeraholic. Begeisterter Schöpfer. Böser Web-Experte. Schriftsteller.“

:quality(85)/cloudfront-us-east-1.images.arcpublishing.com/infobae/OQZKS4MXGNDMRA5OENGLVEH6UQ.jpg)

More Stories
Von Taylor Swift bis George Clooney: Welche Strategien Promis gegen Jetlag haben
Heutiges Jubiläum: Fand am 25. April statt | Veranstaltungen in Argentinien und auf der ganzen Welt
Hersh Goldberg-Pollin sagt, die israelische Regierung sollte sich „schämen“, dass die Hamas ein Video einer in Gaza entführten israelischen Geisel veröffentlichte, in dem sie Netanyahu kritisierte