
AMD Kürzlich veröffentlichte er ein Patent zur Verteilung der Last vom Display auf mehrere GPU-Chips. Die Spielszene wird in einzelne Blöcke aufgeteilt und auf Holztafeln verteilt, um die Verwendung von Schattierungen in Spielen zu verbessern. Dazu wird ein zweistöckiger Folienbehälter verwendet.
AMD veröffentlicht ein Patent zur Implementierung von GPU-Chiplets zur besseren Nutzung der Shader-Technologie
Ein neues von AMD veröffentlichtes Patent eröffnet weitere Einblicke in die Pläne des Unternehmens mit GPU- und CPU-Technologie der nächsten Generation in den kommenden Jahren. Ende Juni wurde bekannt, dass 54 Patentanmeldungen zur Veröffentlichung eingereicht wurden. Es ist nicht bekannt, welches der mehr als fünfzig veröffentlichten Patente in AMDs Plänen verwendet wird. Die in den Patenten diskutierten Anwendungen veranschaulichen den Ansatz des Unternehmens in den folgenden Jahren.
Eine App, die Community-Mitglied @ETI1120 auf der Website bemerkt hat ComputerbasisPatentnummer US20220207827, diskutiert kritische Bilddaten in zwei Phasen, um eine große Menge an Display von der GPU effizient über mehrere Chipsätze zu leiten. Diese CPU wurde Ende letzten Jahres erstmals beim US-Patentamt angemeldet.
Wenn Bilddaten auf der GPU standardmäßig gerastert werden, übernimmt die Shader-Einheit, auch ALU genannt, die ähnliche Aufgabe und weist einzelnen Pixeln einen Farbnamen zu. Im Gegensatz dazu werden die texturierten Polygone, die in dem ausgewählten Pixel in einer gegebenen Spielszene gefunden werden, direkt auf das Pixel abgebildet. Schließlich behält die formulierte Aufgabe atypische Prinzipien bei und unterscheidet sich nur durch andere Texturen, die sich in verschiedenen Pixeln befinden. Diese Methode heißt SIMD oder Single Instruction – Multiple Data.
Für die meisten aktuellen Spiele sind Shader nicht die einzige Aufgabe, die die GPU hervorgebracht hat. Stattdessen werden nach der anfänglichen Schattierung viele Nachbearbeitungselemente eingefügt. Aktionen, die die GPU hinzufügen wird, sind beispielsweise die Verhinderung von Anti-Aliasing, Vignettierung und Blockierung in der Spielumgebung. Das Raytracing tritt jedoch zusammen mit der Schattierung auf, wodurch eine neue Berechnungsmethode entsteht.
Wenn wir über die GPU sprechen, die die Grafik in heutigen Spielen steuert, steigt die vom Computer generierte Last exponentiell auf Tausende von Recheneinheiten an.
Bei Spielen auf GPUs beträgt diese Rechenlast im Idealfall mehrere tausend Compute Units. Dies unterscheidet sich von Prozessoren darin, dass Anwendungen speziell geschrieben werden müssen, um mehr Kerne hinzuzufügen. Der CPU-Scheduler erstellt diese Aktion und teilt die Arbeit von der GPU in verständlichere Aufgaben auf, die von Recheneinheiten verarbeitet werden, auch Binning genannt. Das Bild aus dem Spiel wird präsentiert und dann in separate Blöcke unterteilt, die eine bestimmte Anzahl von Pixeln enthalten. Der Block wird von einer Grafikprozessor-Untereinheit berechnet, wo er synchronisiert und erzeugt wird. Nach diesem Vorgang werden die zu zählenden Pixel bis zur endgültigen Verwendung der Grafikkartenuntereinheit in einem Block zusammengefasst. Es werden Überlegungen zum Schattieren von Rechenleistung, Speicherbandbreite und Cache-Größen angestellt.
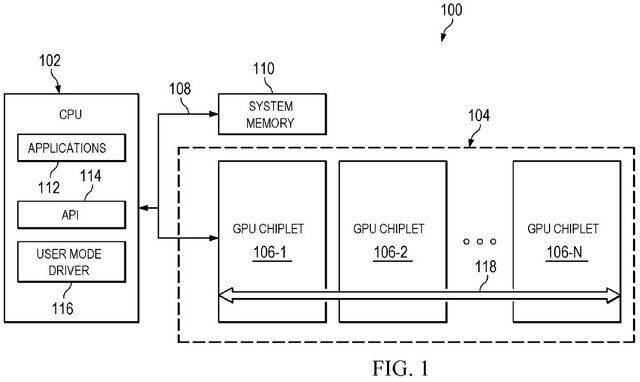
AMD gibt im Patent an, dass das Partitionieren und Verbinden eine umfassende und vollständige Datenverbindung zwischen allen Elementen der GPU erfordert, was ein Problem darstellt. Datenlinks, die nicht in der Vorlage enthalten sind, haben eine hohe Latenz, was den Prozess verlangsamt.
CPUs haben diesen Übergang zu Chiplets mühelos gemacht, da sie den Job über mehrere Kerne senden können, was sie für Chiplets sehr zugänglich macht. GPUs bieten nicht die gleiche Flexibilität, was sie mit einem Dual-Core-Präprozessor vergleichbar macht.
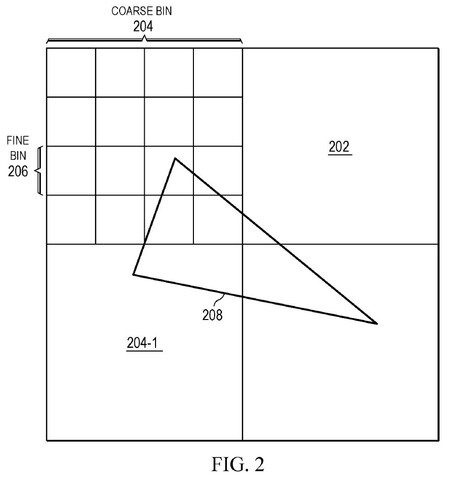
AMD erkennt die Notwendigkeit und versucht, Antworten auf diese Probleme zu geben, indem es die Rasterisierungspipeline ändert und Aufgaben zwischen mehreren GPUs sendet, ähnlich wie bei CPUs. Dies erfordert eine fortschrittliche Binning-Technologie, die das Unternehmen „Binning Binning“, auch als „Binning Binning“ bekannt, anbietet.


Bei der Superassemblierung wird die Teilung in zwei getrennte Phasen statt in eine direkte Verarbeitung in Pixel-für-Pixel-Blöcke verarbeitet. Der erste Schritt besteht darin, die Gleichung zu berechnen, eine 3D-Umgebung zu nehmen und aus dem Original ein 2D-Bild zu erstellen. Die Phase wird als Vertex-Shader bezeichnet und wird vor der Rasterung abgeschlossen, und der Prozess ist im ersten Chip der GPU sehr gering. Sobald die Spielszene fertig ist, beginnt sie zu verblassen und entwickelt sich zu gezackten Kästchen und Verarbeitung in einem einzigen GPU-Chip. Danach können Routineaufgaben wie Punktierung und Nachbearbeitung beginnen.


Es ist nicht bekannt, wann AMD beabsichtigt, dieses neue Verfahren zu verwenden, oder ob es genehmigt wird. Es gibt uns jedoch einen Einblick in die Zukunft einer effizienteren GPU-Verarbeitung.
Nachrichtenquellen: ComputerbasisUnd die Kostenlose Patente online

„Professioneller Internet-Junkie. Bacon-Fanatiker. Freundlicher Gamer. Bierfreak. Analyst. Twitter-Fan.“




More Stories
Windows 11-Startmenü-Anzeigen werden jetzt für alle bereitgestellt
Eiyuden Chronicle: Hundred Heroes-Patch-Updates sind bereits verfügbar
Ich habe das ganze Wochenende Fallout 76 gespielt und es hat mir irgendwie gefallen